Abstract
Learning real-world robotic manipulation is challenging, particularly when limited demonstrations are available. Existing methods for few-shot manipulation often rely on simulation-augmented data or pre-built modules like grasping and pose estimation, which struggle with sim-to-real gaps and lack extensibility. While large-scale imitation pre-training shows promise, adapting these general-purpose policies to specific tasks in data-scarce settings remains unexplored. To achieve this, we propose ControlVLA, a novel framework that bridges pre-trained VLA models with object-centric representations via a ControlNet-style architecture for efficient fine-tuning. Specifically, to introduce object-centric conditions without overwriting prior knowledge, ControlVLA zero-initializes a set of projection layers, allowing them to gradually adapt the pre-trained manipulation policies. In real-world experiments across 6 diverse tasks, including pouring cubes and folding clothes, our method achieves a 76.7% success rate while requiring only 10-20 demonstrations --- a significant improvement over traditional approaches that require more than 100 demonstrations to achieve comparable success. Additional experiments highlight ControlVLA's extensibility to long-horizon tasks and robustness to unseen objects and backgrounds.
Manipulation Results

Method
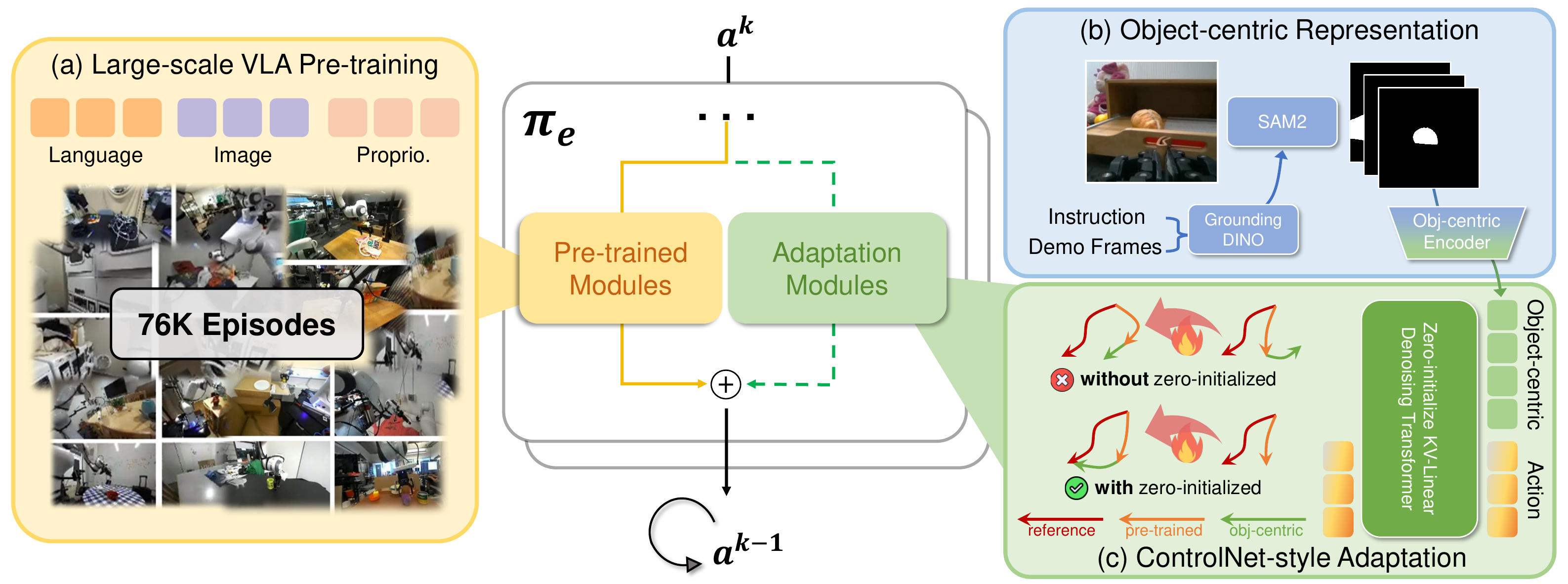
Given a pre-trained general-purpose VLA model, our goal is to efficiently adapt it into a task-specific expert policy using limited demonstrations. To this end, we propose ControlVLA, which employs a ControlNet-style fine-tuning that integrates object-centric representations with a pre-trained VLA model. We first pre-train the general-purpose VLA model on a large-scale, multi-task manipulation dataset, then extract object-centric features to focus learning on task-relevant elements, and finally fine-tune the expert policy by gradually incorporating these features with ControlNet-style fine-tuning strategy. The zero-initialized weights and biases preserve the rich prior knowledge of the pre-trained policy while progressively grounding it in object-centric representation.
Evaluation Setup
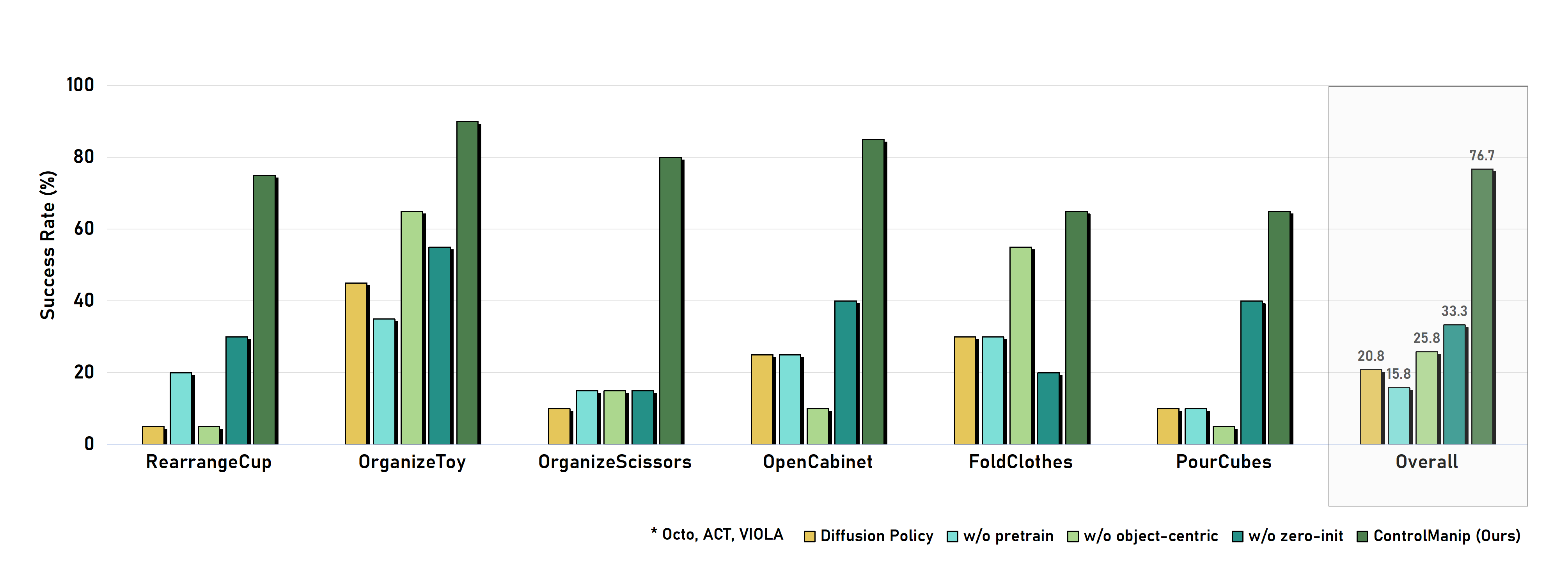
To evaluate the efficiency of ControlVLA, we conduct 8 various real-world tasks using only 10-20 demonstrations.

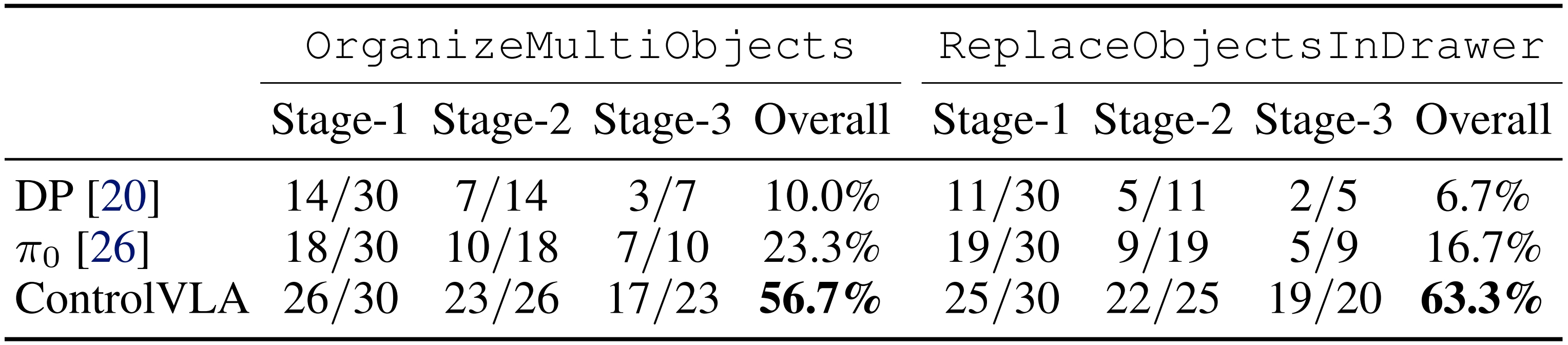
Long-horizon Performance
Adapt ControlVLA to π₀
We further adapt and evaluate ControlVLA on , a more general VLA model, referred to as ControlVLA @ . The model leverages a pre-trained vision-language backbone and introduces a separate action expert that outputs continuous actions using flow matching. ControlVLA @ extends this architecture by incorporating an additional object expert and a set of zero-convolution layers to progressively inject object-centric representation guidance.
Our adaptation method ControlVLA @ consistently outperforms the fine-tuned , demonstrating that ControlVLA can serve as a plug-in module to enhance performance across a wide range of pre-trained VLA models.

Ablations
Citation
@article{li2025controlvla,
title={ControlVLA: Few-shot Object-centric Adaptation for Pre-trained Vision-Language-Action Models},
author={Puhao Li and Yingying Wu and Ziheng Xi and Wanlin Li and Yuzhe Huang and Zhiyuan Zhang and Yinghan Chen and Jianan Wang and Song-Chun Zhu and Tengyu Liu and Siyuan Huang},
journal={arXiv preprint arXiv:2506.16211},
year={2025}
}
powered by Academic Project Page Template